W jednym z poprzednich wpisów omówiliśmy sobie, czym jest Git Flow. Przedstawiony tam sposób pracy z Gitem może dla niektórych wydawać się nieco zbyt rozbudowany i skomplikowany. Szczególnie teraz, gdy coraz większą rolę odgrywają aplikacje webowe, programiści mogą dużo szybciej i częściej dostarczać nowe funkcjonalności. Tempo takich prac bardzo często pozwala na to, aby po deployu zawierającym jakiś bug w programie, zrezygnować z przywracania poprzedniej wersji aplikacji. Dużo szybciej będzie po prostu wykonać kolejny deploy zawierający już poprawkę. Taki sposób rozwoju oprogramowania, będący alternatywą dla Git Flow, nazywamy GitHub Flow.
Jak nie trudno się domyślić, został on opracowany i rozpropagowany przez programistów GitHuba. Znajdzie on głównie zastosowanie w przypadku małych zespołów bądź pracy samodzielnej. Niewątpliwą zaletą GitHub Flow jest jego prostota oraz szybkość dostarczania nowych funkcjonalności (bądź poprawiania błędów).
Koncepcja takiego sposobu pracy jest niedużo młodsza od Git Flow i jednym z pierwszych artykułów na ten temat jest wpis z 2011 autorstwa Scotta Chacona. Polecam tam zajrzeć osobom, które są ciekawe jak w tamtym czasie wyglądał GitHub 🙂
Wszystko to, co do tej pory napisałem, to jednak tylko teoria. Zobaczmy krok po kroku, jak wygląda praca z GitHub Flow.
Jak działa GitHub Flow?
Gałęzie
Model GitHub Flow przewiduje tylko dwa rodzaje gałęzi:
-
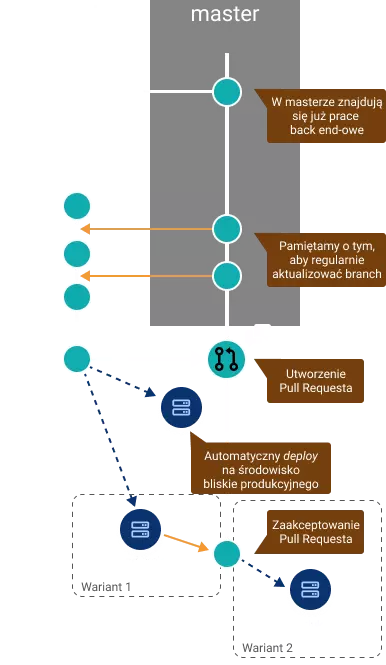
master – na tym branchu znajduje się produkcyjna i aktualna wersja aplikacji. Gałąź ta jest zawsze gotowa do tego, aby w razie potrzeby mogła być deployowana na serwery produkcyjne. To z tej gałęzi programiści będą tworzyć swoje branche i do tej gałęzi mergują swoje zmiany.
-
gałęzie robocze – na tych gałęziach tworzymy nowe funkcjonalności oraz naprawiamy wszelkiego rodzaju błędy w aplikacji.
Flow
W przypadku GitHub Flow staramy się tworzyć małe, samodzielne zadania, nad którymi można pracować w izolacji od innych zadań. Przykład, który podaliśmy sobie w poprzednim wpisie, dotyczył pracy nad formularzem kontaktowym. Zadanie takie powinno zostać podzielone na niezależne zadania, które trafiają do mastera w momencie, gdy zostaną już ukończone. Załóżmy, że nasi koledzy przygotowali już backend i teraz my możemy pracować nad umieszczeniem formularza na stronie.
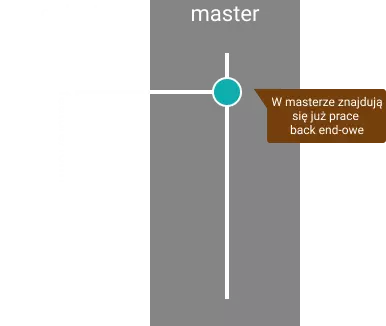
1. Stworzenie brancha
Naszą pracę zawsze zaczynamy wychodząc z master brancha. To w masterze znajduje się przetestowany i działający kod. Dzięki temu wiemy, że pracujemy zawsze na aktualnej wersji aplikacji.
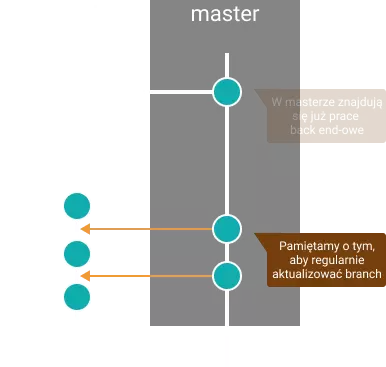
2. Praca nad nową funkcjonalnością
W momencie, gdy jesteśmy już na swoim branchu, możemy zacząć pracę nad zadaniem. Regularnie commitujemy swoją pracę i nie zapominamy o tym, aby aktualizować swoją gałąź o nowe commity z mastera. Jeżeli chcemy mieć liniową i czystą historię to oczywiście najlepiej jest korzystać w tym przypadku z rebase. Zwykły merge jednak też spełni swoje zadanie. Trzymanie naszej gałęzi aktualnej w stosunku do mastera pozwoli nam uniknąć wielu konfliktów w momencie wprowadzania naszych zmian do mastera po zakończeniu pracy.
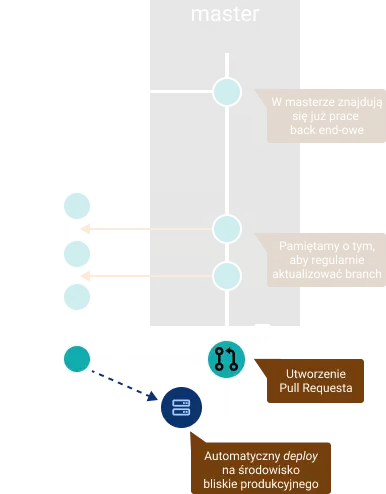
3. Pull Request
Gdy skończymy już nasze zadanie i chcemy je umieścić w masterze, tworzymy tzw. Pull Request. Powiedzieliśmy sobie wcześniej, że master jest gałęzią, z której w każdym momencie możemy wykonać deploy na produkcję. W takim przypadku kod tam się znajdujący musi być dokładnie zweryfikowany przez pozostałych członków zespołu. Pull Request jest miejscem, gdzie możemy dokładnie przedyskutować wprowadzone przez nas rozwiązania.
Dobrą i wskazaną praktyką jest to, aby w trakcie utworzenia Pull Request-a wykonać deploy aplikacji znajdującej się na naszym branchu na środowisko, które możliwie najbardziej odzwierciedla środowisko produkcyjne. Deploy taki najlepiej wykonywać automatycznie zawsze po utworzeniu PR-a. Tam możemy upewnić się, czy nasze zmiany na pewno działają prawidłowo, bądź uruchomić na nim testy automatyczne.
W przypadku, gdy podczas omawiania PR-a wyjdą jakieś błędy, które wymagają poprawki, to poprawiamy je na naszej gałęzi roboczej. Wszystkie przyszłe commity, które wyślemy do zdalnego repozytorium, będą aktualizowały już raz utworzony PR.
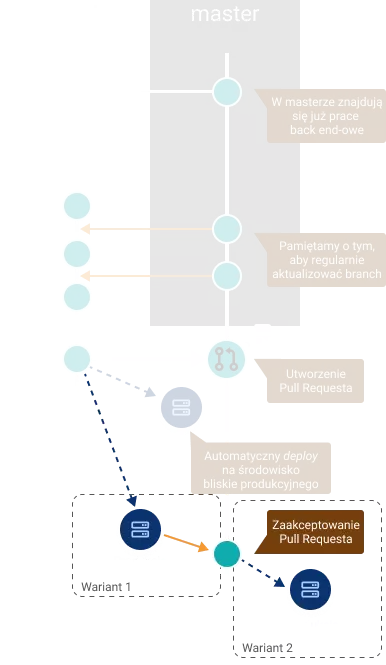
4. Merge i deploy
Gdy nasze zmiany zostały już szczegółowo skonsultowane z pozostałymi członkami zespołu, przyszedł czas na pokazanie ich światu. GitHub Flow jest dość elastyczny, jeżeli chodzi o moment wprowadzenia zmian z brancha na produkcję. Możemy skorzystać z jednego z dwóch wariantów:
- deploy z gałęzi bezpośrednio na produkcję. Jeżeli wszystko poszło zgodnie z planem i aplikacja nie powoduje żadnych problemów, wtedy dopiero mergujemy nasz branch do mastera. Jeżeli coś jest nie tak, wykonujemy deploy wersji z mastera i naprawiamy na naszym branchu wykryte problemy.
- merge zaakceptowanego PR-a do mastera i deploy mastera. Sposób trochę mniej bezpieczny, ale dzięki temu główna gałąź projektu zostaje szybko zaktualizowana o nowe zmiany. Taki proces również dużo łatwiej zautomatyzować za pomocą narzędzi CI/CD. Wszelkie zmiany w masterze mogą powodować automatyczny deploy na produkcję. Problemy wynikłe po deployu naprawiamy kolejnym PR-em. Jeżeli coś pójdzie naprawdę bardzo źle, to mamy przecież Gita – revert bądź reset mogą okazać się pomocne 😉
Problemy i wyzwania
Podczas korzystania z GitHub Flow, podobnie jak z każdym innym modelem pracy, mogą pojawić się pewne wyzwania. Oto kilka z nich, na które warto zwrócić uwagę:
-
Zarządzanie równoczesnymi zmianami. Jednym z największych wyzwań w GitHub Flow jest zarządzanie sytuacją, gdy wiele osób pracuje jednocześnie nad różnymi gałęziami. Istnieje ryzyko, że dwie różne gałęzie mogą wprowadzać sprzeczne zmiany (tzw. konflikt). Jest to szczególnie problematyczne, gdy te zmiany są scalane do mastera w tym samym czasie. Istotne jest więc, aby zespoły miały solidne procesy przeglądania kodu na miejscu i korzystały z narzędzi Git, takich jak
rebase, aby utrzymać historię czystą i zrozumiałą. -
Kontrola jakości kodu. Przy modelu GitHub Flow, gdzie nowe funkcjonalności są często i szybko dodawane do głównej gałęzi, kontrola jakości kodu staje się niezwykle ważna. Wszystko, co jest łączone z masterem, powinno być dokładnie przetestowane i przeglądane pod kątem jakości kodu. To może oznaczać potrzebę silnej kultury przeglądów kodu w zespole, a także efektywnego wykorzystania testów automatycznych.
-
Wymagania dotyczące CI/CD. GitHub Flow opiera się na ciągłej integracji i ciągłym dostarczaniu (CI/CD), co oznacza, że kod jest regularnie łączony z główną gałęzią i wdrażany na produkcję. To z kolei wymaga solidnej infrastruktury CI/CD. Zespoły muszą skonfigurować swoje narzędzia CI/CD tak, aby skutecznie obsługiwać ten proces, co może być wyzwaniem, zwłaszcza dla mniejszych zespołów lub projektów z ograniczonymi zasobami.
Podsumowanie
GitHub Flow jak widać, jest dość prostym podejściem. Być może nawet czytając ten artykuł, właśnie zdajesz sobie sprawę, że używałeś tej metody, nawet o tym nie wiedząc. Podejście, w którym mamy jedną gałąź główną (jeszcze używam nazwy master, ale zauważam, że main jednak robi się coraz bardziej popularne) i jedną gałąź roboczą jest w sumie czymś, czego uczymy się, stawiając pierwsze kroki w Gicie.
Model ten sprawdzi się na pewno w zespołach, które mają możliwość (a czasami również potrzebę) wprowadzania zmian w kodzie raz bądź nawet kilka razy dziennie. W przypadku gdy podejście to będzie wspierane przez dobrze przygotowane narzędzia CI/CD (jak również testy automatyczne), możemy naprawdę ułatwić sobie pracę i rozwijać nasz produkt/aplikację/stronę w tempie szybszym niż konkurencja 🙂
Masz uwagi lub sugestie do tego wpisu?